
某金融企业大批量消息压测延迟基于信创数据库性能故障及优化解决
前言:
数据库作为存储企业数据的重要资产和构筑企业数据管理体系的核心要素,已成为当前信创产品的替换重点。随着国产数据库在企业数据库中应用的占比增加,国产数据库的使用中必然会遇到各种各样的故障,则需要我们的数据库运维人员去及时分析和解决。本文主要介绍国产数据库在一个应用系统压测过程中遇到的性能问题的解决和优化案例。
一、优化案例背景概述
本案例为某金融类企业的一个消息推送类业务系统开发测试过程中遇到的性能问题。该业务系统在进行压测时,测试人员反馈,在进行大批量消息发送时,发现系统存在消息通知推送延迟,甚至整个系统运行效率下降的现象。为提高系统运行效率,技术部门组织相关专业技术人员进行综合的分析优化。
首先针对业务场景进行分析,该消息通知类系统属于对响应时间相对要求较高的系统,因单次推送的消息通知数量较大,当系统后台对于单条通知消息处理能力下降时,在乘积效应的影响下,整体运行效率容易导致数百倍的效率下降,从而造成业务队列出现大量阻塞,造成明显系统性能下降。在进行业务系统层面的日志分析判断的基础上,应用开发人员使用ARTHAS工具排查了前端应用程序的流程耗时,可定位大部分时间在JDBC数据库响应过程,系统性能下降的主要原因在于数据库后端响应的时间变慢,因此本次优化的主要内容侧是针对后端达梦数据库中的性能优化。
二、分析及优化
本文从性能故障现象出发,对于数据库性能的优化,需要对数据库服务器系统资源使用、数据库系统资源使用及数据库进程堆栈信息、数据库SQL等层面进行逐层分析优化。详细排查思路整体逐步阐述。
本次压测环境配置进行梳理如下:
OS:Release: Kylin Linux Advanced Server release V10 ;
虚拟化平台:国产云平台虚拟机,配置为32C/64G;
交换机:H3C 10GE 堆叠交换机;
存储:华为OceanStorage 18510 V5 全闪存储,SAN网络分配块存储至云平台;
服务器:联想的sr658h v2
数据库版本:DM8;
2.1. 服务器资源分析
考虑对数据库服务器的CPU/内存/磁盘使用情况进行分析:
CPU:对服务器资源进行分析排查过程中,发现在进行批量消息发送的业务高峰期中,通过top命令检查,数据库的CPU逐渐升高,在业务高峰期CPU达到90%,但CPU Wait较多。
内存:在故障现象发生时对数据内存情况进行排查,数据库服务器整体内存使用不高,数据库进程占服务器总内存(64G)的 35%左右,因此可基本判断,服务器的内存不存在瓶颈。
磁盘:通过iostat检查数据库服务器在业务高峰时的IO吞吐情况,发现数据库服务器中检测磁盘性能异常,在有大量入库的场景下,磁盘读写速度只有几兆,并且产生了等待,同时底层存储也有延时告警,如下图:
存储端:为了进一步分析磁盘情况,针对磁盘IO响应时间变长的问题,通知存储管理员针对该虚拟机使用的额集中式存储进行检查,发现此时存储提供给本虚拟机使用的LUN的响应延时存在变长的现象,IO平均时延提升至约30ms。因此,存储的性能提升是一个优化方向。
本业务系统业务响应要求高,在特定业务场景下并发量大,会有大量磁盘读写操作,对磁盘性能要求较高。对应的优化方案是可通过迁移存储或者提高该数据库使用的lun的IO优先级,保证集中式存储提供充足的IOPS;
2.2. 数据库SQL分析
此外,对于数据库本身的分析调优也在同步开展。针对本业务模块调研中了解,在该业务的主要的数据库操作为查询,其次为插入入库和修改,直接影响业务运行效率的功能,主要是一条查询语句,并且该SQL只有一条简单表的查询,需要查询的表只有4个字段,数据量约300w行,且在查询条件相关的字段已经建有索引,语句本身的语法不存在问题,针对该sql的执行计划优化空间非常有限。
2.3.数据库慢日志以及内存分析
(1)数据库慢日志分析
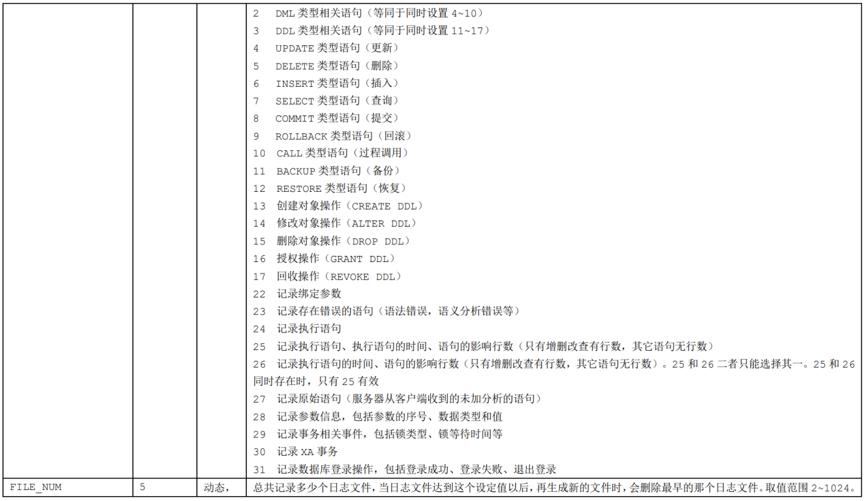
前端日志显示该SQL执行结果的返回时间,在业务高峰期,由正常的10ms以内下降至100ms以上。DM8数据库,在安装是默认是开启了500ms以上慢日志记录的(记录sql但不记录参数),此前,数据库管理员为了检查数据库的sql执行时间,在数据库中调整慢日志记录阈值,从默认的500ms调整至100ms,并同时开启了参数记录。慢日志的调整属于在线参数,无需重启数据库服务。慢日志在sqllog.ini参数文件中SVR_LOG=1时启用,也可以调用命令进行开启或关闭慢日志,如下:
sp_set_para_value(1,'SVR_LOG',1); --开启慢日志
sp_set_para_value(1,'SVR_LOG',0); --关闭慢日志
如果是修改sqllog.ini,可对慢日志多个参数进行修改。
修改前:SQL_TRACE_MASK = 2:3:25 ##不记录参数
修改前:MIN_EXEC_TIME=500 ##慢日志阈值500ms
修改后:SQL_TRACE_MASK = 2:3:22:25:28 ##记录SQL中的传参
修改后:MIN_EXEC_TIME=100 ##慢日志阈值调整至100ms
修改完成后,执行SP_REFRESH_SVR_LOG_CONFIG();更新内存中对应的参数值以使所做的修改生效。
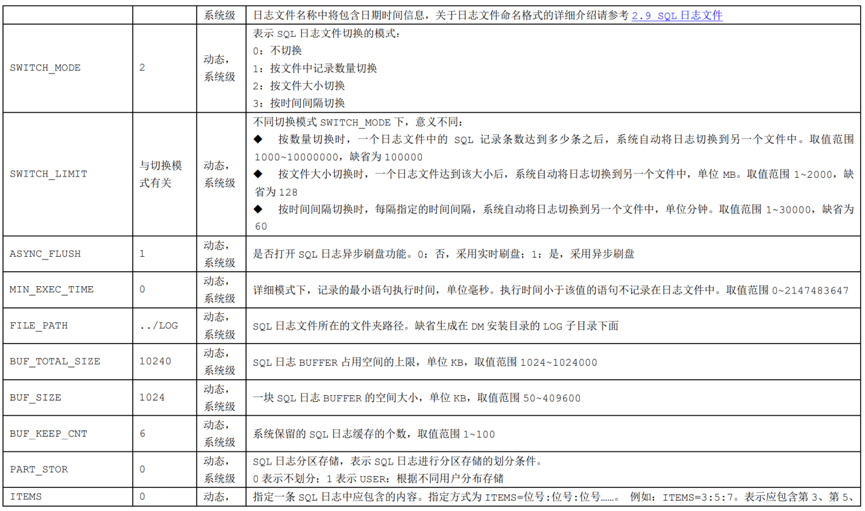
sqllog.ini配置文件参数信息如下图,或访问官方技术社区查看:
https://eco.dameng.com/document/dm/zh-cn/pm/physical-storage#2.1.1.5%20sqllog.ini


但数据库记录的慢日志分析结果并未记录到对应该业务的查询SQL语句,故而可以判断SQL的执行时间不高于100ms。进一步收集50ms慢日志发现,绝大部分SQL执行时间在50毫秒以内,与业务日志分析的大量sql结果返回耗时在100-1000ms范围内不一致,因此还需要深入排查客户端获取sql执行结果耗时超过100ms原因。
为了排除网络传输造成的额外延时,网络、操作系统管理员进行了客户端和数据库服务端的抓包分析,通过dcpdump抓包结果分析,数据包在网络上传输耗时基本为2ms以内,可以忽略。因此还是需要继续深入排查数据库端的耗时。
考虑数据库查询数据的执行返回效率,数据库管理员与达梦数据库研发人员进行了流程梳理,Dm数据库在打开了慢日志的情况下,sql的执行,是经过SQL获取、SQL记录,执行计划分析,SQL执行,慢日志记录等步骤完成后,才将SQL执行结果返回给客户端,因此慢日志的阻塞,也将影响sql结果的返回效率。为此,需检查相关达梦本身系统级的运行情况,以及影响sql返回相关环节的组件运行情况分析。慢日志分析发现对应业务语句不慢,但应用监控到耗时仍在数据库,为了分析数据库运行内部情况,针对DM进程进行了堆栈分析。可以采用系统工具gdb和pstack在线分析堆栈信息。
对故障时间的堆栈进行分析发现,在日志中显示有大量慢日志相关进程在堆积,同时通过select count(*) from v$sessions;查询活跃会话,发现在数据库繁忙期间,数据库活跃会话会增高,会话数在几十甚至上百,活跃会话数高说明数据库此时处于繁忙处理状态,此时初步明确为慢日志方面等待造成了会话处理相关的异常。
分析可能是慢日志记录本身的同步等待,造成了业务日志分析的sql结果返回耗时与数据库慢日志记录SQL执行耗时的不一致。
因此,数据库管理员关闭慢日志的sql以及参数记录,观察数据库和应用端状态,此时数据库堆栈显示无慢日志相关线程,且数据库活跃会话数较低,仅个位数,性能异常现象消失,应用整体恢复常规性能状态。

在确定性能问题来自慢日志记录后,进一步对慢日志配置进行分析排查,结合业务场景和配置分析发现,当前配置会产生大量慢日志,同时考虑到在进行基线配置时,慢日志缓冲区大小当前配置仅有 1M,在开启慢日志记录参数时如果碰到大并发压测,记录相关的参数的量很大,占用了本就不足的磁盘 IO,5 分钟是否开启记录参数日志量对比,开启慢日志参数记录时5分钟日志产生约153MB,不开启参数记录时,约704KB,日志记录相差约 200 倍。
为进一步确认慢日志缓冲区造成的影响,在进行压测时,调大了慢日志缓冲区至30MB后进行观察。同样是在sqllog.ini文件中调整BUFF参数:
调大缓冲区后的堆栈无慢日志相关线程堆积,数据库活跃会话低在个位数,应用端业务执行正常,无性能异常现象,业务效率恢复正常。

同时对比了开启记录参数时慢日志缓冲区不同大小时的使用状态,在产生性能问题时慢日志缓冲区空闲空间为 0,调大后空闲数量为3,空闲空间充足。

慢日志监控可以通过dem对V$SYSSTAT视图里的慢日志缓冲区剩余分配数量进行监控,若剩余分配数量为0时发出告警,STAT_VAL为统计值,例如下图: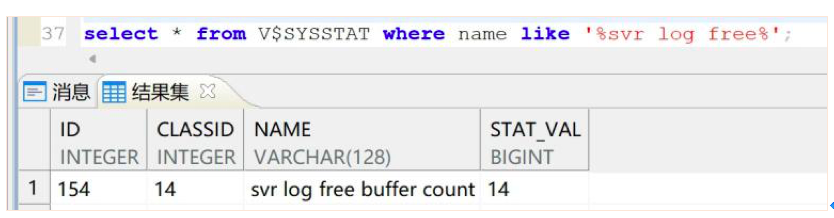
(2)数据库buffer分析
对DM数据库内存使用进行分析。数据库Buffer使用情况主要通过v$bufferpool视图进行查看,常用命令如下,其中NORMAL缓冲区等于参数BUFFER的值。

查询结果如下:
发现此套数据库的buffer大小为10GB,随着并发业务量的增大,NORMAL缓冲区buffer 过小导致命中率很低,说明buffer不足,缓存很快被淘汰从而产生直接的磁盘IO,加重了磁盘IO负担,结合服务器资源使用率来看,服务器的内存使用率偏低,仍有30GB内存剩余,因为数据库内存参数没有及时调整,导致服务器资源没有充分利用。可以调整buffer的大小,一般可优化该参数置服务器内存的一半,该服务器总体内存64GB,该参数可通过SP_SET_PARA_VALUE(2,'BUFFER',30000) 优化至30GB,提高缓存命中率。该参数为静态参数,需要重启生效。
三、案例分析总结
该案例主要针对国产DM8数据库,在磁盘性能较差且慢日志记录量较大情况下,慢日志无法快速落盘,导致慢日志线程缓存区一直处于不足状态,而会话线程需要将SQL执行的相关记录信息转存到慢日志线程缓冲区后才会将执行结果集返回给客户端,因此产生了结果集返回客户端的等待现象,继而表现为应用整体响应存在延时,但慢日志中 SQL 执行时间不慢的现象。同时数据库数据缓存区及慢日志线程缓冲区设置不合理,进一步加重了性能问题的影响。最终可通过优化慢日志的记录阈值、优化慢日志缓存区大小进行调优。
综合进行调优经验:
1) 评估是否需要记录参数,若不必要可关闭参数记录,减少日志产生量。
2) 对于需要记录参数慢日志的系统,如需记录参数,建议监控和及时扩容慢日志的缓存区大小;
3) 需持续关注数据库CPU/内存/存储性能,需结合考虑后端集中式存储吞吐以及相应能力。建议采用有独立IO资源的磁盘存放慢日志等措施减小慢日志记录带来的负面影响;
4) 关注数据库的buffer使用情况,如果buffer太小,也会给IO带来额外的压力,可以及时监控和调整数据库缓存大小,优化读写性能;
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞4本文隶属于专栏

作者其他文章
评论 3 · 赞 9
评论 4 · 赞 17
评论 4 · 赞 6
评论 6 · 赞 11
评论 2 · 赞 14
添加新评论3 条评论
2024-04-08 08:56
2024-04-02 10:15
2024-03-14 15:16